Конечно многие сочтут лишним объяснения КАК работают регулярные выражения, но мне почему-то кажется, что 99% сложностей как раз и связано с непониманием принципа работы RE. Потому я решил нелишним напомнить, как происходит разбор RE.
Рассмотрим простейшее регулярное выражение
/A/
Это выражение ищет в строке букву 'A'. Реализация тривиальная:
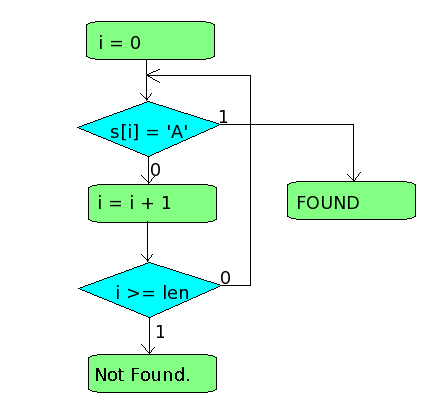
- Начнём с начала строки s, при этом позиция i у нас будет равна 0 (индексы отсчитываются от нуля).
- Проверяем очередной символ s[i] на равенство его нашему шаблону 'A'.
- В случае если s[i] == 'A', мы нашли совпадение, выход.
- Если совпадения нет, увеличиваем индекс, переходя к следующему символу.
- Проверяем, не закончилась-ли строка.
- Если символы ещё есть, переходим к п2.
- Иначе выходим, поиск не удачный.
Это всё прекрасно, однако что делать если шаблон более сложен? Например
/ABC/
Для этого можно просто немного изменить наш алгоритм: после нахождения 'A' мы проверяем следующие буквы, до тех пор, пока не найдём полное совпадение:
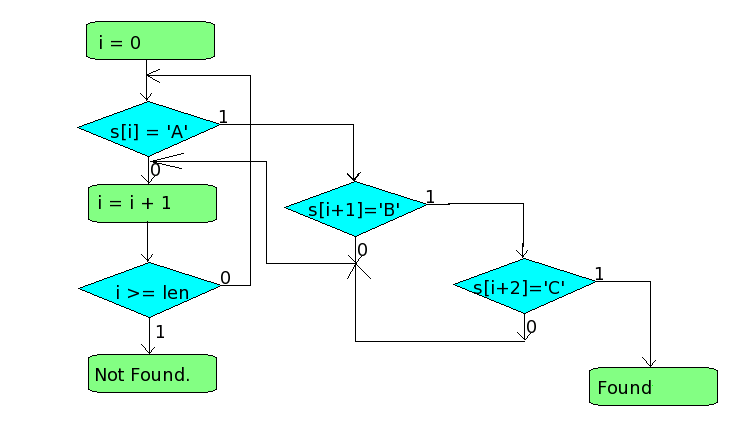
Это работает, но очень медленно: во первых мы часто будем просматривать один символ множество раз (особенно если в нашей строке много букв 'A'), кроме того, при каждом просмотре необходимо проверить, есть-ли ещё символы (проверка у нас есть, но она проверяет только наличие s[i], а вот есть-ли у нас s[i+1] и s[i+2] - неизвестно). Что-бы это исправить, мы сделаем не одну, а три проверки:
- Мы всегда проверяем является-ли символ буквой 'A'.
- Если прошлая буква была «A», мы проверяем, не является-ли текущая буква буквой «B».
- Если прошлая буква была «B», а позапрошлая - 'A', мы проверяем, не является-ли текущая буква буквой 'C'.
Нам понадобится пара временных переменных: e1, которая истинна если выполнился п1, а так-же e2, которая истинна если выполнился п2. Первый пункт мы выполняем всегда, второй только при истинности e1, а третий - если истинно e2. Если на третьем пункте условие выполнилось - шаблон найден.
Замечание
При этом следует учесть, что при проверке мы используем старые значение e1 и e2, те, что вычислены для прошлой буквы.Получается примерно следующая схема:
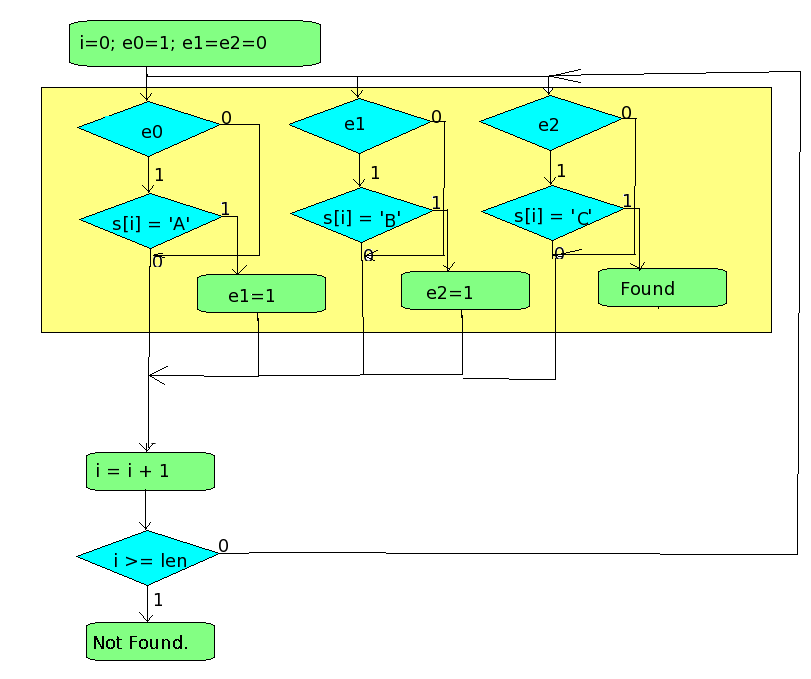
Тут я для единообразия добавил e0, которая всегда истинна.
Ну и где-же тут ускорение? А ускорение тут в том, что за раз мы проверяем по одному условию, но наши процессоры умеют большее: мой например умеет проверять сразу 32 условия, т.к. он 32х битный (я выделил эту проверку в жёлтый прямоугольник). По этой причине я могу все три (максимум 32) проверки сделать за одну операцию, только для каждой проверки мне понадобится таблица в 256 бит (по числу символов), например для буквы «A» моя таблица будет состоять из одних нулей, кроме A-ного символа (65го в ASCII), тогда мне просто надо будет вынуть из таблицы бит, номер которого совпадает с номером символа. А раз я проверяю за раз по 32 условия, мне понадобится 32 таких таблицы, что составляет ровно 1 килобайт. Весь этот набор таблиц я могу вычислить перед поиском, а потом использовать его в случае, если мне опять понадобится поиск по этому шаблону.
Замечание
Этот метод называется SHIFT-AND, т.к. для реализации его достаточно всего двух команд CPU: сдвиг, а потом поразрядное И. Сдвигаю я при этом набор своих временных переменных e0, e1, e2 ... e31.
Предостережение
Тут предполагается, что в одном символе у нас 8 бит, т.е. любой символ укладывается в один байт. Это не так для кодировки UTF-8 (в которой и работают сегодня большинство систем). По этой причине, утилите sed приходится создавать более громоздкие таблицы, и значит тратить намного больше времени на обработку RE. Именно по этой причине, скрипты sed работают в разы дольше, чем более примитивные утилиты.Подсказка
Если вам нужно быстродействие, вы можете отключить поддержку UTF-8, или наоборот, включить её. Для этого нужно поменять следующие переменные shell:export LC_COLLATE=ru_RU.UTF-8 export LC_CTYPE=ru_RU.UTF-8
Кроме ускорения поиска, при таком методе я могу очень просто реализовать нечёткий поиск: к примеру в таблицах для символов (тех, что в 256 бит) я могу помечать единицей не только A, B, и C, но и a, b, и c - это приведёт к тому, что мой шаблон будет работать и с малыми и с большими буквами, например так:
/[Aa][Bb][Cc]/
или вот так:
/ABC/I
(это верно для адресного выражения, для команды s нужно использовать модификатор i).
В действительности, поиск происходит немного по другому: строка просматривается слева направо, но при нахождении поиск не прерывается, просто запоминается позиция начала совпадения. После чего просмотр продолжается в поисках завершения совпадения. Для простых шаблонов это не играет никакой роли, ведь начало совпадения можно легко рассчитать когда совпадение будет полностью найдено. Однако, даже в простых случаях следует учитывать тот факт, что поиск производится по всей строке, а не только до первого совпадения. Именно по этой причине возможно применение числовых модификаторов команды s. По умолчанию полагается модификатор 1, что приводит к запоминанию первого совпадения, кроме того, мы можем указать например модификатор 7, что приведёт к запоминанию именно седьмого совпадения (если оно произойдёт конечно).
Подсказка
Кстати, у sed нет модификатора для нахождения последнего совпадения, он просто не нужен: мы можем записатьs/(.*)X/\1Y/Что приведёт к замене именно последней X на Y.
Предостережение
К сожалению, это срабатывает в том, и только в том случае, если выражение /X/ чётко совпадает, к примеру оно не содержит неопределённых квантификаторов, например `*'. Если выражение /X/ содержит *, то первое выражение /.*/ захватывает максимум, а выражению /X/ остаётся лишь пустая строка. Наиболее просто это решается если /X/ состоит из одного символа, в этом случае вместо /.*/ мы можем записать /[^X]*/, и тогда мы добьёмся ожидаемого поведения нашей конструкции, к примеру, выделить ссылку в HTML тексте мы можем так:/<a href="([^"]+)"[^>]*>/
Шаблоны с квантификаторами обрабатываются так-же: сначала ищется первое совпадение, а потом поиск повторяется необходимое число раз. К примеру /X{1,2}/ найдёт первое X и запомнит его позицию, а далее будет снова искать X, если он найдётся, то завершением совпадения считается окончание этого второго X (конечно X может быть любым подвыражением, а не только одиночным символом). Если второе X не найдётся, окончанием будет служить позиция окончания первого X (эта позиция тоже запоминается, но если будет найдено второе X, то новая позиция завершения затирает старую). Как видите, sed никогда не возвращается к уже просмотренным символам.
Вы можете обсудить этот документ на форуме. Текст предоставляется по лицензии GNU Free Documentation License (Перевод лицензии GFDL).
Вы можете пожертвовать небольшую сумму яндекс-денег на счёт 41001666004238 для оплаты хостинга, интернета, и прочего. Это конечно добровольно, однако это намного улучшит данный документ (у меня будет больше времени для его улучшения). На самом деле, проект часто находится на грани закрытия, ибо никаких денег никогда не приносил, и приносить не будет. Вы можете мне помочь. Спасибо.