Замечание
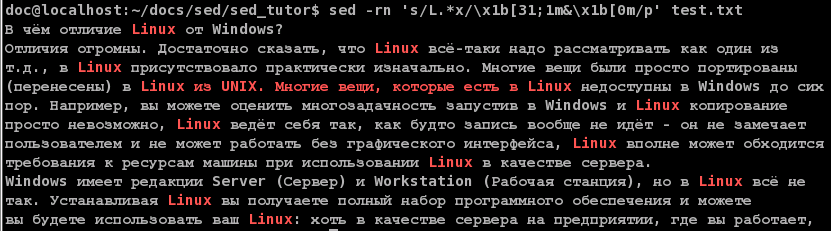
Здесь и далее будут картинки. В картинках всё намного виднее. Я использую стандартные коды: например \x1b31m означает тёмно-красный цвет, \x1b31;1m - светло-красный.-n говорит о том, что печатать ничего не надо, всё печатает сам скрипт, командой s, с модификатором p, да и то, если шаблон нужный найдётся. Ампресанд (&) - это особый символ в выражении для замены, как и «\0» он означает - всё что нашлось. Как видите, в большинстве случаев результат ожидаемый, вот только...
Linux из UNIX. Многие вещи, которые есть в Linuxв тех случаях, когда обрабатывается строки, в которых есть 2 буквы «x», sed захватывает слишком много. Нам хотелось-бы выделить оба слова, а вовсе не всё вместе. Конечно в php или в перле можно использовать не жадные выражения, у нас это невозможно. Что-же делать? Самое простое - захватить не любой символ, а любой кроме «x».
![Поиск шаблона L[^x]*x](img/snapshot7.png)
Безусловно, это очень просто, и это - работает. Но не всегда... Что-же делать, если у нас не «x», а что-то более сложное, например «ux»? Т.е., мы желаем найти подстроки, которые начинаются на «L», и кончаются на «ux», причём не жадно, только маленькие. У нас нет нежадных выражений, у нас так-же нет отрицаний, мы не можем записать "найди подстроку, где нет «ux»" Потому приходится извращатся.
$ sed -rn 's/(L.*ux).*/\1/;T;s/[^L]*L/L/;p' test.txt Linux Linux Linux Linux из UNIX. Многие вещи, которые есть в Linux Linux Linux Linux Linux Linux Linux LinuxКак видите, это почти всегда работает, это уже хорошо, осталось совсем чуть-чуть. Что-же я сделал? В первой команде s, я искал строки, в которых есть буква «L», за которой идёт «ux», а после них - что угодно. Да, первая звёздочка слишком жадная, и иногда она захватывает (как мы видим) слишком много - не беда. Этой-же командой я отрезал хвост - заключив нужное в скобки, а затем написав в выражении для замены \1. Обращаю ваше внимание - башка, то что идёт перед «L» - так и осталось висеть, это тоже не важно, важно, что я нашёл то, что нужно! А вот теперь, я применяю команду T - она завершает скрипт тогда, и только тогда, когда замена не состоялась. Тем самым, я отсеиваю ненужные строки, и перехожу уже к анализу нужных. А мне сейчас надо вырезать всё то, что идёт перед «L». Тут я воспользовался выше рассмотренным приёмом - я вырезаю всё то что не L. И далее - печатаю. Сейчас задача упростилась: достаточно вырезать всё то, что идёт после первого «ux»:
$ sed -rn 's/(L.*ux).*/\1/;T;s/[^L]*L/L/;s/(ux).*/\1/;p' test.txt Linux Linux Linux Linux Linux Linux Linux Linux Linux Linux LinuxХа! Тот-же самый эффект был-бы получен выражением
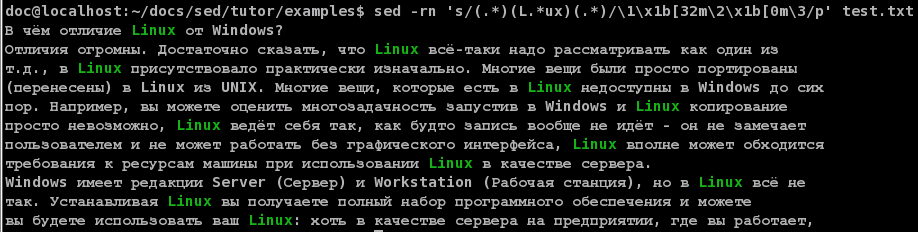
Вот только это так только в данном случае - дело в том, что в четвёртой строке затесался второй Linux, а не первый, как мы ожидали... Это связано тоже с жадностью - звёздочка жадная, и первая-же звёздочка пожрёт всё что сможет, в том числе и букву «L» и весь первый «Linux» (даже несмотря на то, что он подходит под шаблон в скобках).
Предположим, нам надо найти и выделить какие-то подстроки среди текста. Они находятся между временем и IP-адресом, при этом, нам необходимо использовать не жадные выражения, т.е. из
asdffggh 00:12:21 jfkd 12:38:46 kfkldfkfdlf 192.168.1.2 jfkjdjf 81.66.1.43
нам надо выделить
12:38:46 kfkldfkfdlf 192.168.1.2
В данном случае, я использую маркёры, особые байты для разделения текста. В исходном тексте этих маркёров не бывает, потому я могу искать и выделять подстроки между маркёрами, а вовсе не между сложными подвыражениями. Например ip это
/([0-9]{1,3}\.){3}[0-9]{1,3}/при этом подвыражения надо ещё и сохранять, в отличие от маркёров, значение которых известно, и сохранять потому их не требуется.
В качестве маркёров проще всего использовать символ перевода строки «\n», просто потому, что ни в одной загруженной sed строке такого символа нет, и быть не может. Впрочем на практике я могу использовать и другие байты, главное - в исходном тексте их быть не должно, иначе мы запутаемся. Использование перевода строки - хорошая идея, однако она не слишком удобна при отладке. В качестве маркёров часто можно использовать и символы которые часто встречаются в тексте, конечно с осторожностью, что-бы не запутаться. К примеру, при анализе логов, я использовал маркёр `~', он может быть в логах, но мне нужно было отфильтровать дату в начале, а вот в дате `~' не встречается.
В моём тестовом файле нет символа Q, и для наглядности именно его я и буду использовать в качестве маркёра (не забывайте, это всего-лишь пример!). А искать я буду тоже намного более простое - просто символы между «о» и «а» - это можно сделать намного проще, но я рассматриваю общий случай: вместо «о» (и «а») может быть сверхсложное регулярное выражение. Просто в моём тестовом примере множество хитрых комбинаций этих букв.
Во-первых ограничим область поиска: если на прошлой страничке я использовал для этого команду T', то сейчас я воспользуюсь адресом, я буду обрабатывать только строки, в которых есть /о.*а/, при этом всю обработку я заключу в фигурные скобки - «{}».
Хм... Вот тут ИМХО проще сделать всё с двумя маркёрами, в качестве второго можно использовать например «\r», которого нет ни в одном Linux-тексте, а если такой текст и есть - то это можно исправить, просто стерев этот символ
Замечание
Windows-редакторы вставляют вовсе не «\n» в конце строки, а комбинацию «\r\n». А вот в компах от корпорации Apple принято завершать строку символом «\r».В примере-же я буду для наглядности использовать нерусскую букву «T», таких букв у меня тоже нет. Т.к. надо искать совпадение между «о» и «а», то мы вставим «Q» перед «о», и «T» после «а»:
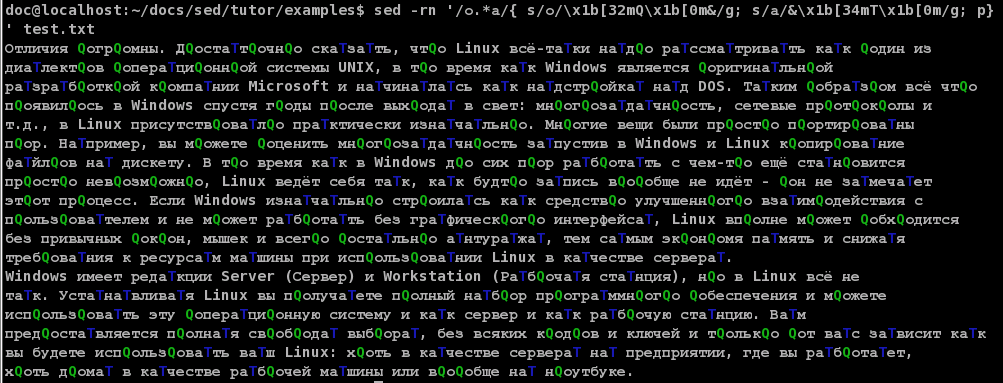
Глядя на этот результат, можно легко сформулировать нужное правило: нам требуется найти первое «Q», после которой идёт «T», причём между этими «Q» и «T» не должно быть других маркёров. Буквально перекладывая это в регулярные выражения получаем
/.*Q([^QT]*)T.*/
Вот только такое RE найдёт вовсе не первое, а последнее совпадение! Проще всего сделать всё это в два приёма: сначала отрубить хвост:
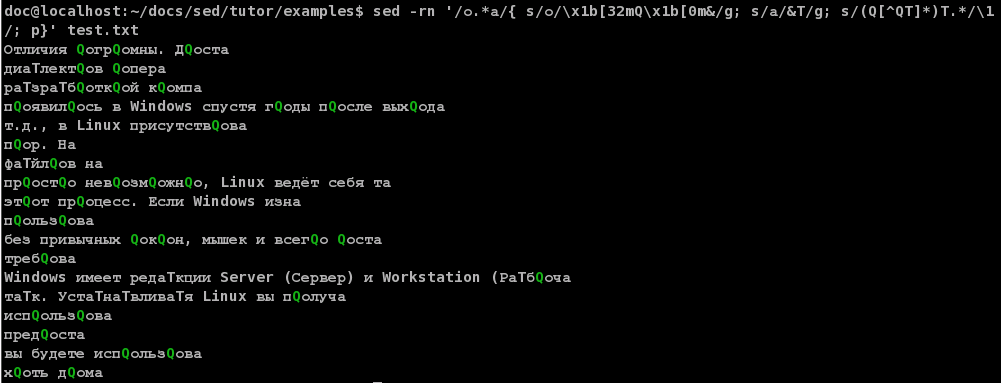
А теперь рубим голову, от начала, и до последней Q:
$ sed -rn '/о.*а/{ s/о/Q\0/g; s/а/\0T/g; s/(Q[^QT]*)T.*/\1/; s/.*Q//; p}' test.txt
оста
опера
омпа
ода
ова
ор. На
ов на
о, Linux ведёт себя та
оцесс. Если Windows изна
ова
оста
ова
оча
олуча
ова
оста
ова
омаВот - тут и пригодилась жадность - звёздочка пожрала все «Q» до последней!
Вся прелесть использования маркёров в том, что мы помечаем какую-либо подстроку одиночным символом, что позволяет нам во-первых резко уменьшить сложность и громоздкость скриптов, во-вторых позволяет использовать отрицание - мы не можем написать выражение, которое НЕ подходит, например мы не можем написать: найди «X», в котором нет «Y», если «Y» - не тривиально, однако, используя маркёры мы можем это сделать - «[^Y]» совпадает с любым символом исключая «Y».
В некоторых случаях есть смысл не добавлять, а заменять что-то маркёром, тогда, когда это что-то одинаковое, либо оно нам не понадобится - это конечно сильно ускоряет работу наших скриптов. Кстати, о быстродействии: не следует думать, что такие извраты сильно замедляют работу скриптов по сравнению скажем с тем-же перлом (там часто можно просто ограничить жадность) - дело в том, что не жадные квантификаторы и в перле работают медленно, и часто программеры их используют не оправдано, в sed-же мы используем такие извращения только в тех редких случаях, когда это действительно необходимо.
Вы можете обсудить этот документ на форуме. Текст предоставляется по лицензии GNU Free Documentation License (Перевод лицензии GFDL).
Вы можете пожертвовать небольшую сумму яндекс-денег на счёт 41001666004238 для оплаты хостинга, интернета, и прочего. Это конечно добровольно, однако это намного улучшит данный документ (у меня будет больше времени для его улучшения). На самом деле, проект часто находится на грани закрытия, ибо никаких денег никогда не приносил, и приносить не будет. Вы можете мне помочь. Спасибо.