Вообще-то, в нормальном режиме sed обрабатывает строки по одной, однако, часто требуется обрабатывать несколько строк, давайте попробуем сэмулировать вимовское gqap, это выравнивание строк по левому краю, с шириной столбца не более N (кстати, для этого у sed есть команда L). Положим N == 40, и возьмём наш текст. Алгоритм видимо будет следующим:
- читаем строку
- (цикл) Добавляем к строке ещё строки, пока строка не станет больше или равна N
- У нас сейчас в буфере много коротких строк, мы делаем из них одну длинную
- Теперь отрезаем от строки кусок, не более N, и выводим его.
- Удаляем этот кусок, и переходим к п2.
Ну первый пункт sed сама сделает, за нами остальное. Как видите, что-бы не усложнять я опустил тут выход из скрипта - понятно, что когда-то он закончится, нам нужно будет всего-лишь проверить корректность завершения, и в случае чего внести коррективы (тут надо быть внимательным, обычно и так работает, но вы должны проверить все точки, где возможен выход из скрипта). Есть ещё одна проблема: мы проверяем длину в цикле, однако мы не всегда сможем корректно разрезать строку, проблема в том, что резать мы можем только по пробелам и переводам строки. Если мы загрузим слишком длинную строку без пробелов, то мы не сможем её порезать. Я попробую вставить склейку внутрь цикла, и проверять с учётом этого случая.
Сложности конечно возникают, вот как например посчитать длину строки? Ну например /.{40}/ это ровно сорок символов,
Замечание
На самом деле, это не ровно 40 символов - это как минимум сорок символов, хотя их может быть и больше. Регулярное выражение найдёт 40 символов, однако в буфере при этом могут находится и другие символы.я было написал /.{40}\S*/, это получилось сорок символов, за которыми может быть ещё сколько-то не пробельных символов, т.е. строка большая или равная N, а нам нужна меньшая или равная. Что-ж, и такое выражение можно составить: /.{,40}\s/. Это от 0 до 40 символов, за которыми стоит один пробельный символ.
Вот что получилось в итоге:
Пример 4.5. Выравнивание по левому краю.
#!/bin/sed -rf
:begin_loop
/.{40}/! {
# если у нас ещё меньше чем 40 символов, то мы загрузим
# ещё одну строчку
N
# если загруженная строчка пустая, то мы
# выводим этот хвост и выходим(хвост короче 40), то-же происходит,
# если строк больше нет.
/\n$/ b
# команда N добавила нам \n, меняем его на пробел
s/\n/ /
# продолжаем цикл
b begin_loop
}
# в строке больше 40 символов - отрезаем хвост
# тут используется жадность квантификатора - он стремится захватить как
# можно более длинную строку
s/^(.{,40})\s/\1\n/
# если хвост отрезан, (точнее отделён \n), тогда переходим к печати.
t end_loop
# особый случай - строка длиннее 40 символов, однако разрезать её нельзя.
# попробуем отрезать хоть как-то, пускай у нас иные строчки будут слишком
# длинные, но только те, которые никак не порезать
s/^(\S+)\s/\1\n/
:end_loop
# печать. печатается только отрезанная строка до первого \n
P
# следующая команда вырезает только-что распечатанную строку,
# и переходит к метке begin_loop, без загрузки сл. строки
D
В этом скрипте только первая строка вводится как обычно, из скрипта нет обычного выхода, скрипт заканчивается на команде D, а эта команда вовсе не запускает новый цикл, и новая строка не грузится, дело в том, что эта команда примерно соответствует командам
s/[^\n]*\n// b begin_loop
Т.е., удаляет из буфера первую строчку, а затем переходит к началу скрипта. Скрипт завершает свою работу в другом месте, а именно в команде N, если входной поток кончился, то N ничего не вводит, а переходит к завершению цикла, где содержимое буфера выводится в выходной поток.
Команда s способна работать в особом, многострочном режиме. Попробуем создать текст из 4х строк:
$ echo -e "A\nB\nC\nD" A B C D
А теперь загрузим этот текст целиком в буфер:
$ echo -e "A\nB\nC\nD" | sed -rn 'N;N;N;p' A B C D
тут первая строка загружается автоматически, а потом к ней добавляется ещё 3, и то что получилось распечатывается. Получается то-же самое. Но если сменить все переводы строки на что-то другое, мы сразу увидим разницу:
$ echo -e "A\nB\nC\nD" | sed -rn 'N;N;N;s/\n/~/g;p' A~B~C~D
Таким образом, у нас в буфере оказалось сразу 4 строки разделённые \n. Попробуем найти начало строк:
$ echo -e "A\nB\nC\nD" | sed -rn 'N;N;N;s/^/~/g;p' ~A B C D
Как видите, находится только начало первой строки, для того, что-бы найти начало всех строк как раз и нужен модификатор m команды s:
$ echo -e "A\nB\nC\nD" | sed -rn 'N;N;N;s/^/~/mg;p' ~A ~B ~C ~D
С этим модификатором можно найти начало любой строки в буфере. Кроме того, концы строк так-же можно найти с помощью символа «$». Для поиска начала первой строки служит прямая кавычка «\`», а для поиска конца последней строки, в этом режиме применяется экранированная обратная «\'».
Выше мы рассмотрели выравнивание по левому краю, тут нет ничего сложного, лишь бы строки были не длиннее некоторого предела. Вообще говоря, выравнивание - это когда строка имеет фиксированную длину равную N, длинные строки обрезаются, а для коротких добавляются пробелы. Разрезать мы разрезали, но пробелов не добавили - просто справа они подразумеваются, и выводить их не нужно.
Не очень сложно выровнять порезанный текст не по левому, а по правому краю: для этого надо просто добавить слева N-l пробелов, где l - длинна строки. Именно так-бы я и сделал на C, но в sed своя специфика: у нас нет вычитания. Что-ж, сделаем по другому - добавим слева 40 пробелов, а потом вырежем 40 последних символов (подразумевается, что справа у нас нет оконечных пробелов, если ваш текст такое содержит, то надо предварительно очистить его, например командой s/\s*$//, конечно это команда sed).
Пример 4.6. Выравнивание по правому краю.
#!/bin/sed -rf
1{
# подготовка области удержания - создание строки
# из 40 пробелов
x
# 10 пробелов
s/.*/ /
# а тут мы каждый пробел меняем на 4, итого - 40
s/ / /g
x
}
# подгружаем пробелы и переносим их в начало строки
G
s/(.*)\n(.*)/\2\1/
# теперь берём последние 40 символов
s/.*(.{40})$/\1/
Перед выравниванием по правому краю надо выровнять по левому, что-бы все строки были не длиннее 40 символов. Если текст длиннее - то лишние символы обрежутся.
Замечание
В info sed так-же есть похожий пример.Выровнять текст по центру сложнее - для этого нужно сначала добавить пробелов справа, что-бы все строки были строго из N символов, а затем половину правых пробелов перенести влево. Сложность конечно в вычислении половины. Но это довольно просто, если использовать жадность, и тот факт, что все символы (пробелы) одинаковые. Ровно половину пробелов можно выделить так
s/(.*)\1/\1/
Звёздочка может вообще не захватывать символов, и это - допустимо, может так-же захватить 1 пробел, а \1 ещё один, может так-же 2 пробела, при этом \1 так-же захватит 2. Но так-как звёздочка жадная - она захватит максимум - ровно половину. А вот и сам скрипт:
Пример 4.7. Выравнивание по центру.
#!/bin/sed -rf
1{
x
s/.*/ /
s/ / /g
x
}
G
s/(.{41}).*/\1/
s/(.*)\n(.*)\2/\2\1/
А если N-l нечётное? А вы сами подумайте, почему в этом случае всё корректно работает ;)
Раз уж речь пошла о выравнивании, то нужно захватить и последний случай. Что-бы выравнять строку по обоим краям, проще всего вставлять пробелы внутрь строки до тех пор, пока строка не станет в N символов. Необходимо предусмотреть случай, когда строка последняя в абзаце, такие строки выравнивать не нужно. Абзацем будем считать строки, которые оканчиваются пустой строкой. Вот сам скрипт:
Пример 4.8. Выравнивание по левому и правому краю.
#!/bin/sed -rf
N
/\n$/ b
h
s/\n.*//
t begin_loop
:begin_loop
/.{40}/ b end_loop
s/([^ ]) ([^ ])/\1 \2/
t begin_loop
s/([^ ]) ([^ ])/\1 \2/
t begin_loop
s/([^ ]) ([^ ])/\1 \2/
t begin_loop
g
P
D
:end_loop
G
s/\n.*\n/\n/
P
D
Не так-уж и сложно, и даже работает (только предварительно нужно выравнять текст по левому краю). Скрипт начинается с команды N, которая подгружает следующую строку. Если эта строка пустая - мы выходим из скрипта, распечатывая обе строки (так-же мы выходим если строки нет). Сохранив обе строки в области удержания, мы вырезаем следующую, и начинаем цикл выравнивания текущей. Выравнивание довольно просто - мы ищем дырку из одного пробела между не пробельными символами, и меняем её на дырку из двух пробелов. Как только одиночные дырки кончатся, мы меняем двойные, а затем и тройные. Цикл завершится как только у нас будет ровно 40 символов. Возможен так-же особый случай: у нас может не хватить дырок. В этом случае мы восстанавливаем строки, и печатаем не выравненный вариант.
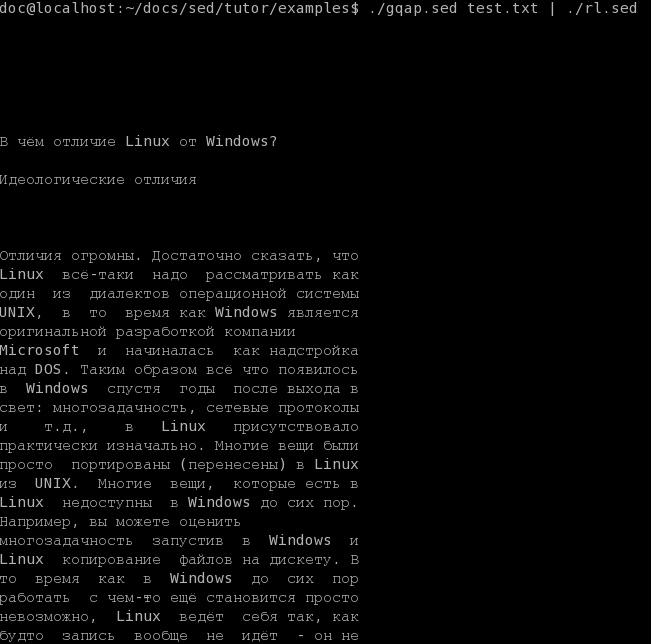
Прежде чем разделять текст на предложения, следует определить само понятие "предложение". Я буду считать предложением любую часть текста, которая оканчивается на [.!?], причём после этого символа должен идти пробел или перевод строки. Кроме того, предложение завершается, если после него идёт пустая строка.
Перед разделением на предложения срежем пробелы в начале и в конце строки и удалим пустые строки.
Мы сделаем вложенный цикл: во внешнем неявном цикле мы будем резать строки отделяя предложения символом '\n', а затем печатая по одному предложению командой P, после чего распечатанное предложение мы сотрём командой D, которая и продолжит внешний цикл.
Во вложенном цикле мы будем клеить строчки, если предложение не завершено. Для загрузки следующей строки мы воспользуемся командой N, и проверим особый случай - пустая строка, которая так-же завершает предложение. После загрузки новой строки, мы заменим загруженный символ '\n' на пробел.
Пример 4.9. разделение на предложения.
#!/bin/sed -rf # удаление пробелов в начале и в конце строки s/^\s+// s/\s+$// /^$/ d t start :start # поиск первого предложения s/([.!?])\s/\1\n/ t print_p # если строка последняя, то печатаем и выходим $ b # грузим следующую строчку N # проверяем, не является-ли загруженная строка пустой s/\n\s*$// # мы загрузили пустую строку - значит прошлая строка это предложение t # предложение продолжается и в следующей строке, меняем перевод строки # на пробел s/\n/ / # этот переход всегда выполняется t start :print_p # печать найденного и отделённого предложения P D
Вы можете обсудить этот документ на форуме. Текст предоставляется по лицензии GNU Free Documentation License (Перевод лицензии GFDL).
Вы можете пожертвовать небольшую сумму яндекс-денег на счёт 41001666004238 для оплаты хостинга, интернета, и прочего. Это конечно добровольно, однако это намного улучшит данный документ (у меня будет больше времени для его улучшения). На самом деле, проект часто находится на грани закрытия, ибо никаких денег никогда не приносил, и приносить не будет. Вы можете мне помочь. Спасибо.