Замечание
Так-же переименование рассмотрено в примере к info sed.Часто файлы после неправильного монтирования или после распаковки с неправильной кодировкой получаются с битыми именами, к примеру вот как выглядит альбом "Зачем снятся сны" Гражданской Обороны, если его записать на флешку в системе с UTF-8, а прочитать в системе с KOI8-R:
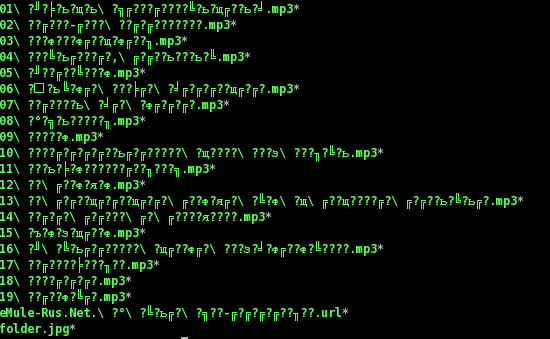
Если посмотреть этот вывод командой hexdump, становится видно, что имена побились безвозвратно - знаки вопроса (?) действительно имеют код «\x3F», и потому то, что было на их месте не подлежит восстановлению.
Замечание
Если бы это было не так, мы могли-бы сконвертировать имя командой iconv, и вернуть первоначальное имя. См. ниже пример.Попробуем переименовать файлы из XXX.mp3, в NN.mp3, где XXX - любые символы, а NN - это номер файла. Для начала, создадим список из имён файлов с номером строки:
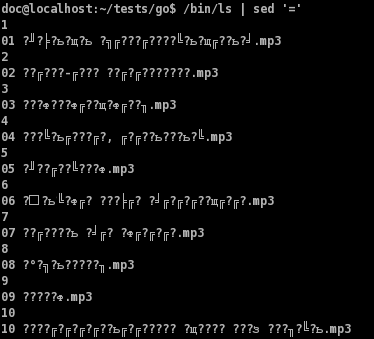
Важно
Здесь я использую /bin/ls, для того, что-бы не сработал никакой алиас. Обычно ls выводит список файлов вместе со всякими добавочными символами, к примеру добавляет `*' к каждому исполняемому файлу. Применение полного пути приведёт к тому, что выполнится именно исполняемый файл /bin/ls, а не алиас. Кроме того, /bin/ls выводит цветной список в несколько колонок, но так-как мы выводим в поток, вывод происходит в одну колонку и без раскраски. На рисунке хорошо видно, что просто ls выдаёт нам совсем не то что требуется.Далее используем следующий скрипт:
$ /bin/ls | sed = |\ sed -rn 'N;s/[a-z0-9_.]*$/\n&/i;s/^([0-9]+)\n([^\n]+)\n(.*)/mv -v "\2\3" "\1\3"/ep'
Здесь обработка имени происходит в несколько этапов:
Во первых мы объединяем имя файла и его номер командой N.
Затем мы отделяем расширение файла. Расширение файла нам пригодится для того что-бы эти файлы не путать, кроме того, обычно расширением является последовательность вполне допустимых символов, которые можно и нужно сохранить. Я считаю допустимыми символы [a-z0-9_.].
s/[a-z0-9_.]*$/\n&/i
Замечание
Тут возможно 2 особых случая:- Расширения может и не быть, в этом случае команда s всё равно выполнится и добавит в конец буфера перевод строки.
- Всё имя файла может состоять из допустимых символов. В таком случае следующая команда s просто не выполнится, и с файлом не произойдёт никаких изменений.
Обратите внимание на модификатор i, он нужен для того, что-бы малые и большие буквы не различались. Часто многие девайсы называют файлы большими буквами (руки бы оторвать кодерам этих девайсов...).
После отделения расширения происходит собственно переименование командой mv:
s/^([0-9]+)\n([^\n]+)\n(.*)/mv -v "\2\3" "\1\3"/ep
Обратите внимание на модификатор + во втором выражении, он нужен для того, что-бы mv не пыталась переименовывать файлы с допустимыми именами. Команда mv выполняется с ключом -v и модификатором ep, для того, что-бы мы видели какие файлы переименовываются.
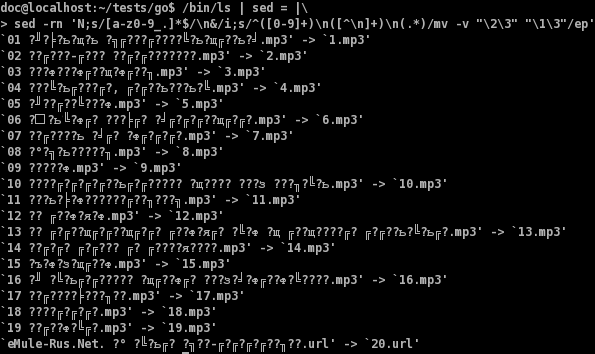
Замечание
На самом деле тут совсем не всё так просто: вместо непонятных символов ОС подставляет знаки вопроса, а эти знаки потом переходят в команду mv и она их обрабатывает как "любой одиночный символ". Бывает так, что этот подход не помогает, например если в имени есть кавычки и/или переводы строки. В этом случае нам поможет команда find, с опцией-printf.
Если имена файлов совсем не читаемые, мы их и читать не будем! Смотрите:
$ find . -type f -printf "%h/%i\n" ./1753457 ./1753458 ./1753463 ./1753461 ./1753464 ./1753468 ./1753453 ./1753470 ./1753465 ./1753462 ./1753467 ./1753450 ./1753456 ./1753452 ./1753469 ./1753455 ./1753454 ./1753451 ./1753459 ./1753460 ./1753466
Что это за хрень? Всё просто: это каталог где лежит файл, а вместо его имени записан его inode. Путь мне тоже нужен, т.к. find просматривает не только каталог, но и его подкаталоги.
Подсказка
Если вам не нужен просмотр подкаталогов, используйте find с опцией-maxdepth 1А теперь делаем так-же как в прошлом скрипте, однако файлы ищем не по имени, а по их inode:
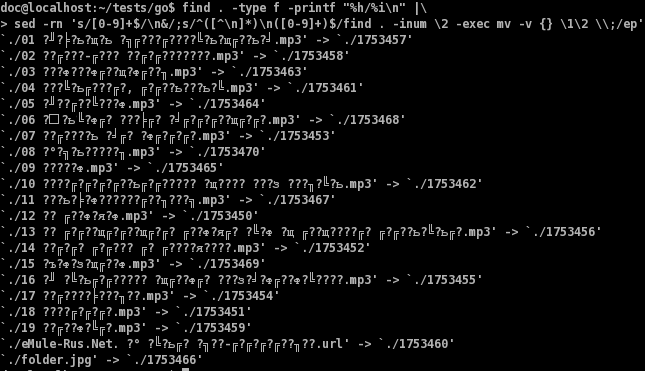
Замечание
На самом деле тут наверное всё-же происходит подстановка битого имени. Внутри команды find.
Замечание
Обратите внимание на двойное экранирование точки с запятой. Для команды find необходимо одиночное экранирование, но в выражении для замены команды s приходится применять ещё одно экранирование. Иначе ; будет без слеша.
Замечание
Многие гуру Linux-а меня сейчас закидают тухлыми помидорами: "Дескать нет у нас никаких расширений! Мы можем называть файлы как захотим, хоть вообще никак!" В чём-то они конечно правы: в имени файла допустимы любые символы (кроме «/» и «\x00»), причём в любом порядке - точки так-же можно ставить как нам угодно. Всё это так, но используя расширения, можно одной командой выполнить любую операцию над любыми типами файлов, и не важно, 10 их или 10000. Любая операция будет выполнена мгновенно! (не, ну сами понимаете, если надо отправить 10000 мб через дайлапный модем, это не мгновенно, но это лучше, чем отправлять их по одному, ручками). А так-как информацию о типе(расширение) мы потеряли вместе с именем, неплохо-бы это восстановить (к тому-же, стукнутые на всю голову маздайщики часто хранят свои вирусы в виде big_tits.jpeg, вирус-то у нас не запустится, но и "картинку" посмотреть не получится, не картинка-то вовсе. Потому есть смысл проверить расширение, а лучше создать его по новому).
Всё-бы ничего, только мы теперь не знаем, что это за файлы, и чем их открывать :( Для исправления этого существует команда file:
$ /bin/ls | sed -rn 's/^[0-9]+$/file &/ep' 1753450: MP3 file with ID3 version 2.3.0 tag 1753451: MP3 file with ID3 version 2.3.0 tag 1753452: MP3 file with ID3 version 2.3.0 tag 1753453: MP3 file with ID3 version 2.3.0 tag 1753454: MP3 file with ID3 version 2.3.0 tag 1753455: MP3 file with ID3 version 2.3.0 tag 1753456: MP3 file with ID3 version 2.3.0 tag 1753457: MP3 file with ID3 version 2.3.0 tag 1753458: MP3 file with ID3 version 2.3.0 tag 1753459: MP3 file with ID3 version 2.3.0 tag 1753460: ASCII text, with CRLF line terminators 1753461: MP3 file with ID3 version 2.3.0 tag 1753462: MP3 file with ID3 version 2.3.0 tag 1753463: MP3 file with ID3 version 2.3.0 tag 1753464: MP3 file with ID3 version 2.3.0 tag 1753465: MP3 file with ID3 version 2.3.0 tag 1753466: JPEG image data, JFIF standard 1.02 1753467: MP3 file with ID3 version 2.3.0 tag 1753468: MP3 file with ID3 version 2.3.0 tag 1753469: MP3 file with ID3 version 2.3.0 tag 1753470: MP3 file with ID3 version 2.3.0 tag
А теперь ещё раз переименуем:
Пример 4.12. Добавление расширения к имени файла.
#!/bin/sed -rnf
/^[0-9]+$/ {
s//file &/e
s/^([0-9]+): (.*)/\2\n\1/
/^MP3 file/ s/$/.mp3/
/^ASCII text/ s/$/.txt/
/^JPEG image data/ s/$/.jpg/
/\n.*\./ s/^[^\n]+\n([0-9]+)(.*)/mv -v \1 \1\2/ep
}
Замечание
Конечно тут добавляются вовсе не все возможные расширения, однако для моего примера этого вполне достаточно. Вы сами можете добавить необходимые вам типы файлов.запускается этот скрипт так:
$ /bin/ls | ./add_ext.sed
Конечно ему надо дать права на исполнение:
$ chmod +x add_ext.sed
Внутри скрипта я анализирую вывод file, и в зависимости от этого прибавляю расширение. Если расширение добавлено, то я переименовываю.
Замечание
Обратите внимание на регулярное выражение в первой команде s, оно отсутствует - используется предыдущее адресное выражение/^[0-9]+$/
Замечание
Далее будет рассмотрен улучшенный вариант этого скрипта.
Вот ещё один пример: требуется сравнить 2 каталога. Сделать это просто, достаточно найти все файлы (не каталоги), в первом каталоге, а затем сравнить их с одноимёнными файлами в другом каталоге
Замечание
только перед этим, командой find -type f|wc -l неплохо посмотреть сколько файлов в каталогах. А то следуя нашему алгоритму, мы не сможем найти "лишние" файлы, которые есть во втором каталоге, но нет в первом.Скрипт очень простой, но он иллюстрирует некоторые тонкие моменты интеграции sed и bash'а.
Пример 4.13. Сравнение каталогов.
#!/bin/sh find $1 -type f | sed -rn " s%^$1/(.*)%cmp '&' '$2/\1';echo \$?%pe /^0$/b p q"
Замечание
После имени первого каталога не должно быть слеша, это можно исправить, но мне лень.
Тут всё просто: благодаря модификатору pe команда сначала выводится, а потом выполняется, что-бы было видно как идёт процесс (можно ещё одну sed добавить, что-бы сделать красиво), а вот результат (это число, 0 если файлы одинаковые) никуда не выводится, а проверяется. Если файлы одинаковые, мы переходим к проверки новой пары, а вот если разные - то мы выводим код возврата и прерываем скрипт. При этом cmp выводит диагностическое сообщение, мы его видим на терминале, т.к. оно идёт в поток ошибок.
Предостережение
Обратите внимание на экранирование $ после echo: это надо, что-бы выполнилась команда echo $?, если слеш не за экранировать, то переменная $? раскроется слишком рано, и будет содержать код возврата find, а вовсе не cmp, как нам нужно. Именно из-за таких фокусов я терпеть не могу скрипты в двойных кавычках. Однако кавычки тут нужны: дело в том, что наш скрипт не работает на файлах с одиночной кавычкой: эта кавычка разбивает имя на две части, причём вторая часть остаётся междузакавыченными частями - что shell естественно понять не может, и выполнять отказывается. Проще всего разделить такое имя на три части:- начало имени 'голова'
- одиночная кавычка, что-бы её передать внутрь shell-команды мы её закавычиваем: "'" Одиночная кавычка не работает внутри двойных.
- Остался 'хвост'.
s/'/'\"'\"'/gв самом начале sed-скрипта.
Замечание
Однако я не вставил эту команду в свой скрипт - потому он не сможет сравнивать файлы с кавычками в именах (попробуйте сами).
Вы можете обсудить этот документ на форуме. Текст предоставляется по лицензии GNU Free Documentation License (Перевод лицензии GFDL).
Вы можете пожертвовать небольшую сумму яндекс-денег на счёт 41001666004238 для оплаты хостинга, интернета, и прочего. Это конечно добровольно, однако это намного улучшит данный документ (у меня будет больше времени для его улучшения). На самом деле, проект часто находится на грани закрытия, ибо никаких денег никогда не приносил, и приносить не будет. Вы можете мне помочь. Спасибо.